Devlog: The DTB Parser Part 1
(Post from 3.12.2025 (DD.MM.YYYY))
This will be a longer devlog because DTB is “simple” but also pretty hard as already mentioned last time. Probably the next days will come more posts because i am already by Paging and made my first tests.
What is DTB?
The dtb is called “Device Tree Blob” and its used on RISC-V (at least i work with it and OpenSBI) to descripe the Hardware on the Board you have. Its good and easy for the Kernel to see what he has, where it is and some more informations (I am also not that deep, i made the Basics for what i needed). Here an example from my kernel logs:  Every entry in a dtb is called a Node, in the example node this represents Memory (RAM) region. Its the device Type Property (exactly under —-Property: device_type) and then cames “reg”, in reg we have (In this example) 4 32 Bit Values, this represents the region where is available(Not everytime, reserved area’s can overlap, this areas are not free Memory to use) Memory for our Kernel (The first 2 are the start address, the last 2 are the size of the region) and after this the Node ends. In the dtb there are tokens, they are 32-bit width and they say “Hey, here a node begins” or “hey, here is a property” (Oversimplified)
Every entry in a dtb is called a Node, in the example node this represents Memory (RAM) region. Its the device Type Property (exactly under —-Property: device_type) and then cames “reg”, in reg we have (In this example) 4 32 Bit Values, this represents the region where is available(Not everytime, reserved area’s can overlap, this areas are not free Memory to use) Memory for our Kernel (The first 2 are the start address, the last 2 are the size of the region) and after this the Node ends. In the dtb there are tokens, they are 32-bit width and they say “Hey, here a node begins” or “hey, here is a property” (Oversimplified)
So, whats hard on a dtb?
It has a standart, but its not strict in some ways, for myself as an example i had the problem that in the early stage i only have the stack as reliable Memory, but the dtb is not fixed, it could have 1 Memory node, but it also could have 55 Memory Nodes (To be fair, in Qemu is it 1 Memory Node like in example, but i want it to be dynamic so on real boards it could work too). And its not fixed then the nodes appear, but it gives some rules to work with. (Like Memory Nodes (and Reserved Memory Nodes) have to be in root)
So what do you do? On my case i made it so that i have fixed size arrays on sizes that are unlikely to have that much of notes (I think the most will be around 1-20 Max) and that the first moment we don’t care about anything in the dtb except for Memory Nodes (and later UART, but thats for another time) so we can find memory that we can use. Here a screenshot from my found Memory: 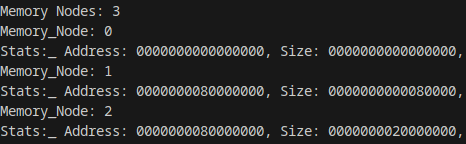
So, what now with available memory?
Now we can begin to make a Heap… or at least preperations for our first Kernel Heap, with a Heap we can be a lot more dynamic with things, like parsing the dtb, for this we need to get every free memory node and adjust the region they are showing as free with reserved Memory areas. I make a bit more then this, but this is a simple explaination. In the end of this we give it to Paging, but this is for another Post.
Thank you for Reading :D