First forays into natural language processing — get rid of a line or keep it?

This post is part of a series on my Data Science journey with PDPC Decisions. Check it out for more posts on visualisations, natural languge processing, data extraction and processing!
Avid followers of Love Law Robots will know that I have been hard at creating a corpus of Personal Data Protection Commission decisions. Downloading them and pre-processing them has taken a lot of work! However, it has managed to help me create interesting charts that shows insight at a macro level. How many decisions are released in a year and how long have they been? What decisions refer to each other in a network?
Unfortunately, what I would really to do is natural language processing. A robot should analyse text and make conclusions from it. This is much closer to the bread and butter of what lawyers do. I have been poking around spaCy, but using their regular expression function doesn’t really cut it.
This is not going to be the post where I say I trained a model to ask what the ratio decendi of a decision is. Part of the difficulty is finding a problem that is solvable given my current learning. So I have picked something that is useful and can be implemented fast.
The Problem
The biggest problem I have is that the decisions, like many other judgements produced by Singapore courts, is in PDF. This looks great on paper but is gibberish to a computer. I explained this problem in an earlier post about pre-processing.
 Love.Law.Robots.Houfu
Love.Law.Robots.Houfu
Having seen how the PDF extraction tool does its work, you can figure out which lines you want or don’t want. You don’t want empty lines. You don’t want lines with just numbers on them (these are usually page numbers). Citations? One-word indexes? The commissioner’s name. You can’t exactly think up of all the various permutations and then brainstorm on regular expression rules to cover all of them.
It becomes a whack a mole.
Training a Model for the win
It was during one of those rage-filled “how many more things do I have to do to improve this” nights when it hit me.
“I know what lines I do not want to keep. Why don’t I just tell the computer what they are instead of abstracting the problem with regular expressions?!”
Then I suddenly remembered about machine learning. Statistically, the robot, after learning about what lines I would keep or not, could make a guess. If the robot can guess right most of the time, that would determine in which cases regular expression must be used.
So, I got off my chair, selected dozens of PDFs and converted them into text. Then I separated the text into a CSV file and started classifying them.
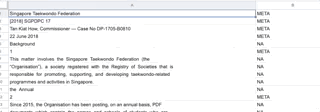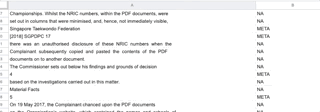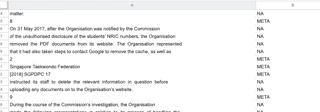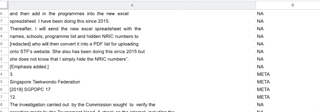 Classification of lines for training
Classification of lines for training
I managed to compile a list of over five thousand lines for my training and test data. After that, I lifted the training code from spaCy’s documentation to train the model. My Macbook Pro’s fans got noisy, but it was done in a matter of minutes.
Asking the model to classify sentences gave me the following results:
| Text | Remove or Keep |
|---|---|
| Hello. | Keep |
| Regulation 10(2) provides that a contract referred to in regulation 10(1) must: | Keep |
| YEONG ZEE KIN | Remove |
| [2019] SGPDPC 18 | Remove |
| transferred under the contract”. | Keep |
| There were various internal frameworks, policies and standards which apply to | Keep |
| (vi) | Remove |
By applying it to text extracted from the PDF, we can get a resulting document which can be used in the corpus. You can check out the code used for this in the Github Repository under the branch “line_categoriser”.
 GitHubhoufu
GitHubhoufuConclusion
Will I use this for production purposes? Nope. When I ran some decisions through this process, the effectiveness is unfortunately like using regular expressions. The model, which weighs nearly 19Mbs, also took noticeably longer to process a series of strings.
My current thoughts on this specific problem is for a different approach. It would involve studying PDF internals and observing things like font size and styles to determine whether a line is a header or a footnote. It would also make it easier to join lines of the same style to make a paragraph. Unfortunately, that is some homework for another day.
Was it a wasted adventure? I do not think so. Ultimately, I wanted to experiment, and embarking on a task I could do in a week of nights was surely insightful in determining whether I can do it, and what are the limitations of machine learning in certain tasks.
So, hold on to your horses, I will be getting there much sooner now.
#PDPC-Decisions #spaCy #NaturalLanguageProcessing
Love.Law.Robots. – A blog by Ang Hou Fu

- Discuss... this Post
- If you found this post useful, or like my work, a tip is always appreciated:
- Follow [this blog on the Fediverse]()
- Contact me: