So what difference does it make? Drawing red lines with Python

Way back in December 2021, I caught wind of the 2020 Revised Edition of the statutes in Singapore law:
Keeping Singapore laws accessible to all - AGC, together with the Law Revision Committee, has completed a universal revision of Singapore’s Acts of Parliament! pic.twitter.com/76TnrNCMUq
— Attorney-General's Chambers Singapore (@agcsingapore) December 21, 2021
The AGC highlighted that the revised legislation now uses “simpler language”. I was curious about this claim and looked over their list of changes. I was not very impressed with them.
However, I did not want to rely only on my subjective intuition to make that conclusion. I wanted to test it using data science. This meant I had to compare text, calculate the changes' readability statistics, and see what changed.
As part of this project, I wanted to see the changes. This should be a piece of cake. After all, Microsoft Word lets you do this with a few clicks.
Python’s difflib: Good for programmers, not so for lawyers
I did not want to reinvent the wheel, which probably would require me to figure out how to implement something called the Levenshtein Difference or “gestalt pattern matching” as an algorithm🤯. Luckily for me, the standard Python library already has a module that allows you to compare text and create a human-readable representation of its changes. It’s called difflib.
If you spend a lot of time programming with Python, you might have already seen it in action. Here’s a sample output from the documentation:
[' 1. Beautiful is better than ugly.\n',
'- 2. Explicit is better than implicit.\n',
'- 3. Simple is better than complex.\n',
'+ 3. Simple is better than complex.\n',
'? ++\n',
'- 4. Complex is better than complicated.\n',
'? ^ ---- ^\n',
'+ 4. Complicated is better than complex.\n',
'? ++++ ^ ^\n',
'+ 5. Flat is better than nested.\n']
As you can see, the start of the lines are marked with - and + at the beginning shows the source and the target lines, while a ? line indicates the changes in the lines. It’s gorgeous and informative.
Feeling awesome, I immediately passed my text into an innocent Differ object from the difflib library. Unfortunately, the results were poor.
This is not pretty. Expand this to see how much so.
source = 'Any person residing in a welfare home may, if so directed by the Director‑General, be removed from that welfare home and admitted to another welfare home.'
compare = 'Any person residing in a welfare home may, if so directed by the Director‑General, be removed from that welfare home and admitted to another welfare home.'
import difflib
d = difflib.Differ()
list(d.compare(source, compare))
Out[1]:
[' A',
' n',
' y',
' ',
' p',
' e',
' r',
' s',
' o',
' n',
' ',
' r',
' e',
' s',
' i',
' d',
' i',
' n',
' g',
' ',
' i',
' n',
' ',
' a',
' ',
' w',
' e',
' l',
' f',
' a',
' r',
' e',
' ',
' h',
' o',
' m',
' e',
' ',
' m',
' a',
' y',
' ,',
' ',
' i',
' f',
' ',
' s',
' o',
' ',
' d',
' i',
' r',
' e',
' c',
' t',
' e',
' d',
' ',
' b',
' y',
' ',
' t',
' h',
' e',
' ',
' D',
' i',
' r',
' e',
' c',
' t',
' o',
' r',
' ‑',
' G',
' e',
' n',
' e',
' r',
' a',
' l',
' ,',
' ',
' b',
' e',
' ',
' r',
' e',
' m',
' o',
' v',
' e',
' d',
' ',
' f',
' r',
' o',
' m',
' ',
' t',
' h',
' a',
' t',
' ',
' w',
' e',
' l',
' f',
' a',
' r',
' e',
' ',
' h',
' o',
' m',
' e',
' ',
' a',
' n',
' d',
' ',
' a',
' d',
' m',
' i',
' t',
' t',
' e',
' d',
' ',
' t',
' o',
' ',
' a',
' n',
' o',
' t',
' h',
' e',
' r',
' ',
' w',
' e',
' l',
' f',
' a',
' r',
' e',
' ',
' h',
' o',
' m',
' e',
' .']
There is no difference between the two lines.
The problem was that when I passed a string of text into Differ, it compared based on the characters. You could see this effect in the documentation example:
'- 4. Complex is better than complicated.\n',
'? ^ ---- ^\n',
'+ 4. Complicated is better than complex.\n',
'? ++++ ^ ^\n',
Instead of detecting that the whole word had changed, difflib noticed that the first four letters were alike.
A simple workaround is to provide Differ with lines instead of a single line of text. This was provided in the documentation by having the \\n (a newline character) as a line separator.
However, trying to break up a single line into several lines doesn’t solve the problem. Once an addition or subtraction to a phrase is detected, the difference propagates itself downstream, and soon the sentences are so different the algorithm gives up.
['- No person shall import or export dutiable goods or tranship goods of a class dutiable ',
'? ^^ ^^^^ ---------\n',
'+ A person must not import or export dutiable goods or tranship goods of a class ',
'? ^ ++ ^^^^^\n',
'- on import except under and in accordance with such regulations or restrictions as are prescribed. ',
'? ------------\n',
'+ dutiable on import except under and in accordance with such regulations or restrictions as are ',
'? +++++++++\n',
'+ prescribed. ']
Once there is an addition or subtraction, the words are marked as changed when they are found in different parts, even though there was no change to the text.
This isn’t difflib’s fault. If difflib’s focus is on source code, then programmers are discouraged from writing long code in a single line. (In PEP-8, a style guide for Python, the maximum line length is 79 characters) Reading words in a giant block of characters is the norm for lawyers. Most legislation I have encountered so far stretches dozens of words over a single sentence 😓.
There’s also another problem anyway. Rightly or wrongly, lawyers don’t expect changes to be rendered this way. The most common method I have seen is using the most powerful LegalTech tool, Microsoft Word, to mark changes.
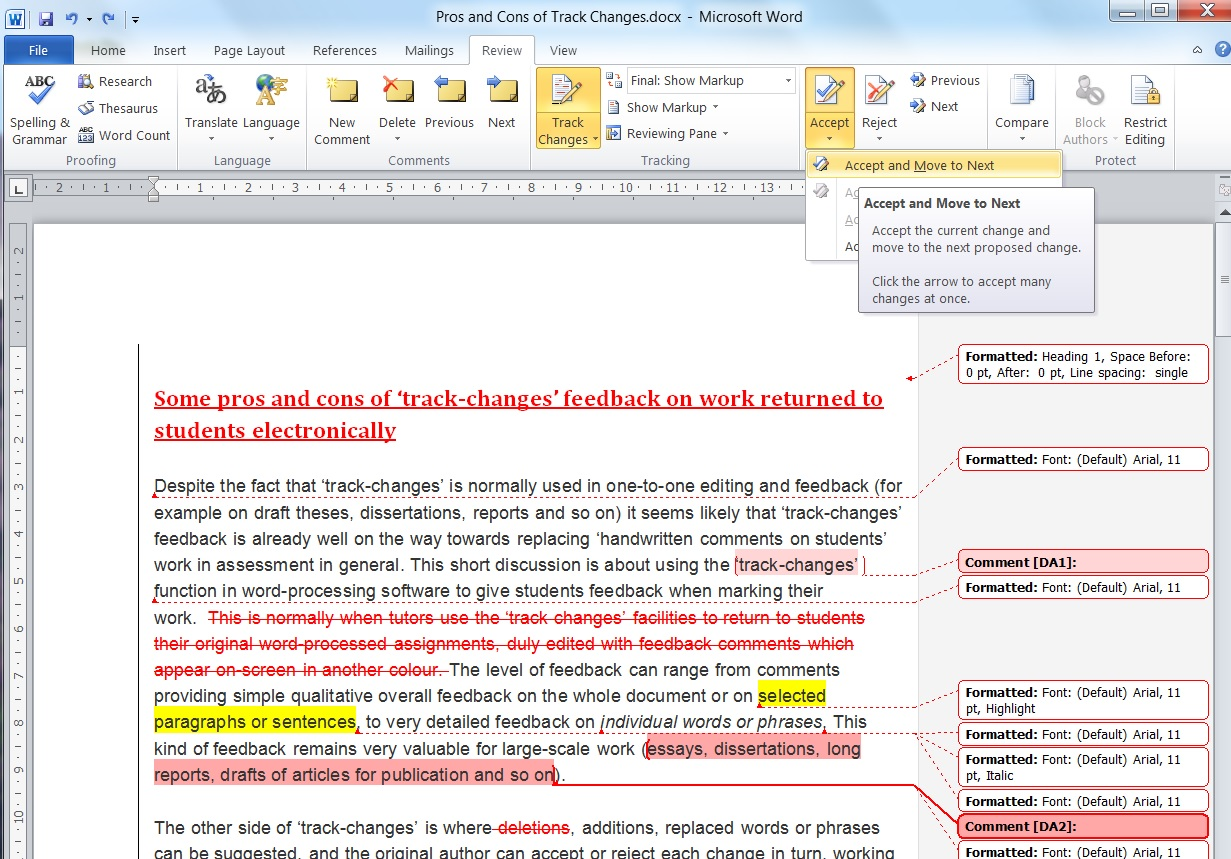
Introducing Redlines — a simple tweak does the trick
So, unfortunately, I needed to do some actual programming. How would I produce a redline comparison out of two texts? Gleaning some experience from solving an earlier problem, I decided to go back to the first principles. What would I do if I were a lawyer trying to redline a document?
It turned out to be quite simple — I would compare words and phrases, not characters.
So, the trick is to tokenise the text first. Tokens, for the most part, are individual words in a sentence. After tokenising the text, you have a sequence of tokens instead of characters. I tried to do this using a regular expression, which worked OK in my opinion.
import re
tokenizer = re.compile(r"((?:[^()\s]+|[().?!-])\s*)")
def tokenize_text(text: str) -> list[str]:
# This function uses re to convert a string into tokens.
return re.findall(tokenizer, text)
Once you have your sequences of tokens to compare, you can get difflibs to do the hard work for you.
Reading the documentation and the source code of difflibs, I found that it provided a low-level SequenceMatcher class. When sequences are compared using that class, it can provide a list of changes needed to convert a source list of tokens to its result. So, breaking that down, you can produce a redline representation instead of the original difflib representation.
def output_markdown(self) -> str:
"""Returns the delta in markdown format."""
result = []
style = 'red'
if self.options.get('markdown_style'):
style = self.options['markdown_style']
if style == 'none':
md_styles = {"ins": ('ins', 'ins'), "del": ('del', 'del')}
elif 'red':
md_styles = {"ins": ('span style="color:red;font-weight:700;"', 'span'),
"del": ('span style="color:red;font-weight:700;text-decoration:line-through;"', 'span')}
for tag, i1, i2, j1, j2 in self.opcodes:
if tag == 'equal':
result.append("".join(self._seq1[i1:i2]))
elif tag == 'insert':
result.append(f"<{md_styles['ins'][0]}>{''.join(self._seq2[j1:j2])}</{md_styles['ins'][1]}>")
elif tag == 'delete':
result.append(f"<{md_styles['del'][0]}>{''.join(self._seq1[i1:i2])}</{md_styles['del'][1]}>")
elif tag == 'replace':
result.append(
f"<{md_styles['del'][0]}>{''.join(self._seq1[i1:i2])}</{md_styles['del'][1]}>"
f"<{md_styles['ins'][0]}>{''.join(self._seq2[j1:j2])}</{md_styles['ins'][1]}>")
return "".join(result)
I liked the results — a simple markdown that can be rendered on any webpage.

I didn’t find anything on the Python Package Index that would have helped me produce a redline representation of text changes, so I published mine anyway. If you found it helpful, feel free to let me know!
Conclusion: Batteries Included
I have always been mystified that Python is described as “batteries included”. Indeed, in this particular case, I found that the standard module had a pretty good solution, and with some tweaks, I was able to make my own. I would never have been able to do this twenty years ago when there was hardly any “stack overflow”, open-source libraries or active developer communities. This also informs my views on what “No Code” should be — batteries included. It’s an exciting time to be involved in code and programming!
#Programming #Python #redlines #DataScience #tutorial #MicrosoftWord
Love.Law.Robots. – A blog by Ang Hou Fu

- Discuss... this Post
- If you found this post useful, or like my work, a tip is always appreciated:
- Follow [this blog on the Fediverse]()
- Contact me: